Google создает таблицы знаний с помощью сложного и мощного алгоритма, который называется Knowledge Graph (Граф Знаний). Этот алгоритм позволяет Google организовывать и представлять информацию связанную с запросами пользователей на более удобный и информативный способ.
Граф Знаний является базой знаний, которая содержит миллионы сущностей (людей, места, организации и т. д.) и связи между ними. Каждая сущность в графе имеет уникальный идентификатор и богатый семантический контент. Граф Знаний строится на основе различных источников данных, включая открытые базы данных, сайты и структурированные данные.
Как только пользователь вводит запрос в поисковую систему Google, алгоритм Knowledge Graph анализирует запрос и ищет связанные сущности и информацию в Графе Знаний. Затем информация о сущностях и их связях отображается в виде расширенных результатов поиска, таких как боковая панель с информацией о конкретной сущности, краткий ответ на вопрос или карусель с релевантными результатами.
Для создания таблиц знаний Google использует множество технологий и алгоритмов, таких как обработка естественного языка, семантический анализ текста, машинное обучение и распознавание образов. Все это позволяет Google выявить и организовать информацию, которая будет наиболее полезна для пользователей.
Одним из примеров использования Графа Знаний является функция "Featured Snippets" (выделенные отрывки), которая показывает краткий ответ на вопрос пользователей прямо в результатах поиска. Это позволяет пользователям получать ответ на свои вопросы без необходимости переходить на другие веб-сайты.
Google ставит перед собой цель предоставить пользователям наиболее точную и полезную информацию в ответ на их запросы. Создание таблиц знаний с помощью Графа Знаний позволяет Google сделать поиск еще более удобным и легким для пользователей. Таким образом, они могут получать нужную информацию быстро и без лишних усилий.
- Влияние графа знаний быстро растет, и его необходимо включить в вашу стратегию SEO.
- Что такое таблица знаний?
- Как Google определяет релевантность сущностей, предоставляющих таблицу знаний?
- Как Google создает таблицы знаний?
- В этом патенте описывается, как Google может выбирать репрезентативные изображения для сущностей типа "Лицо" в соответствующей таблице знаний.
- Доступ к выбору возможных изображений
- В этом патенте изображения выделяются с помощью особенностей. Изображения могут быть сопоставлены с конкретными сущностями. Эти признаки сначала определяются путем распознавания исходного изображения. Дополнительные признаки добавляются через похожие изображения и похожие признаки сущностей, возможно, одного и того же типа. Таким образом, раскрывается смысл изображения.
- Что касается голосового поиска, то здесь важную роль играют такие функции SERP, как функциональные сниппеты и таблицы знаний.
Влияние графа знаний быстро растет, и его необходимо включить в вашу стратегию SEO.
С годами в Google Serps наблюдается рост присутствия панелей знаний. В результате классический результат поиска, также известный как "10 синих ссылок", получает больше конкуренции, когда речь заходит о внимании пользователей.
Или вы предпочитаете называть их "вопросами"? Это связано с тем, что большинство поисковых вопросов являются неявно сформулированными вопросами, требующими ответа.
Google хочет немедленно отвечать на вопросы, используя свои функции SERP. Эти характеристики являются окнами в графе знаний или прямо или косвенно связаны с ним.
В этой статье объясняется, как Google создает таблицы знаний и как они работают.
Что такое таблица знаний?
Сущности играют прямую или косвенную роль во многих вопросах поиска. Поэтому для многих поисковых вопросов в SERPs встречаются различные варианты коробок.
Это связано с тем, что Google знает, что он выдается в поисковых вопросах как вопрос сразу после того, как субъект спрашивает о таблице знаний. Таблицы знаний, называемые каркасами сущностей, также могут быть предоставлены практически любому типу сущностей.
Однако таблицы знаний предоставляются не для каждой сущности типа. Сущности должны быть запечатлены в графе знаний.
Один из основных вопросов SEO — какие сущности должны быть включены в граф Google: согласно Google, в граф знаний в первую очередь записываются только номинальные сущности из следующих категорий сущностей
- Книги и серии книг
- Образовательные учреждения, органы власти, местные магазины и предприятия
- События
- Фильмы и серии фильмов
- Группы и альбомы
- Люди
- Запчасти
- Спортивные команды
- Телесериал
- Видеоигры и ряды
- Веб-сайты или области
Однако не все сущности в этих категориях связаны с таблицами знаний, представленными в SERP. Организации должны обладать социальной значимостью или престижем в соответствующих областях.
Классическую таблицу знаний можно узнать по кнопке поделиться в верхней части таблицы.
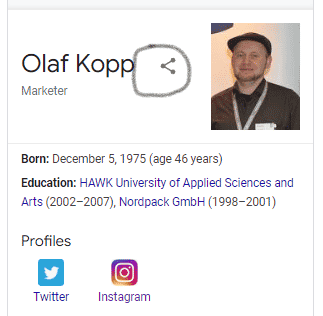
Таблицы знаний не следует путать с бизнес-каркасами. Они основаны на записях Google Business, а не на графах знаний; неясно, в какой степени данные из Google Business учитываются в графах знаний, но это маловероятно.
Google использует различные стандарты для своих таблиц знаний. Значки для содержимого таблицы знаний зависят от типа искомой сущности или сущностей. Заполнители основаны на стандартных характеристиках соответствующего типа сущности.
Как Google определяет релевантность сущностей, предоставляющих таблицу знаний?
Критерии, по которым Google оценивает эту релевантность, четко не задокументированы или нет конкретных заявлений со стороны Google.
Википедия играет особую роль в сущности доказательства. Самый надежный способ распознать организацию — это наличие записи в Википедии.
Однако другие платформы, предоставляющие полуструктурированные данные, такие как SoundCloud, также могут быть использованы Google для идентификации объектов, как, например, взлом ключевых слов, продемонстрированный "SEO Services India".
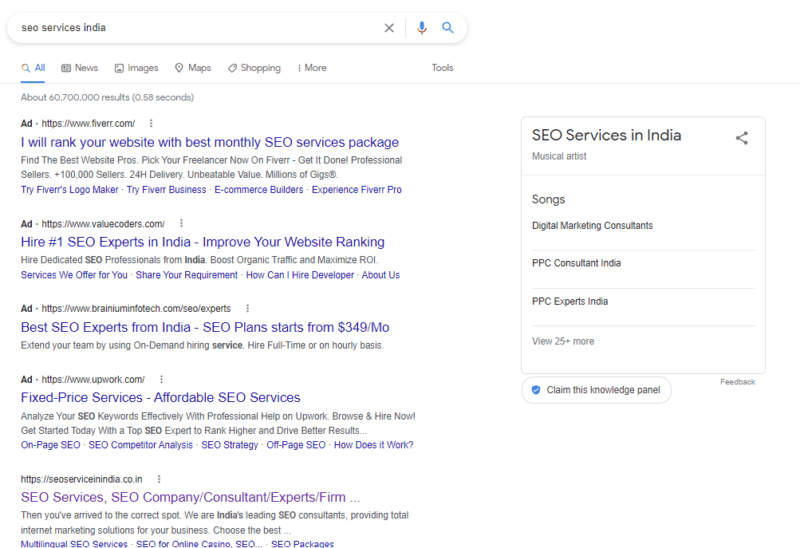
Таким образом, становится ясно, что SoundCloud был использован в качестве источника для обнаружения сущностей: такие сайты, как SoundCloud и Wikipedia, всегда представляют информацию с последовательной структурой. Это означает, что информация может быть легко экспортирована с веб-сайтов без какой-либо разметки.
Как Google создает таблицы знаний?
Таблицы знаний впервые появились в SERPs в 2012 году с появлением Графа знаний.
Патент Google "Предоставление результатов поиска по панелям знаний" описывает основную методологию и назначение панелей знаний. Цели для пользователей поисковой системы следующие.
'Таблицы знаний могут улучшить поисковый опыт пользователя, особенно для запросов, направленных на обучение, просмотр или открытие. Например, таблицы знаний предоставляют пользователям основную фактическую информацию или краткую информацию о конкретном объекте, на который ссылаются в поисковом запросе. Таблицы знаний помогают пользователям легко и естественно ориентироваться в соответствующем контенте. Таблицы знаний могут предоставлять новый контент, который пользователи могут не встретить, если они не выберут несколько результатов поиска. База знаний также может помочь пользователям получить информацию быстрее, чем это было бы необходимо в противном случае. Нажмите на несколько результатов поиска, чтобы получить информацию".
Ниже приводится выдержка из патента на метод предоставления таблицы знаний.
'Методы, системы и устройства для предоставления таблицы знаний, содержащей результаты поиска, включая компьютерные программы, закодированные на компьютерном носителе информации. В одном аспекте метод включает в себя получение результатов поиска в соответствии с полученным запросом. Фактическая сущность, на которую ссылаются, — это запрос. Содержимое идентифицируется для отображения в таблице знаний фактической сущности. Контент включает по меньшей мере один элемент контента, полученный из первого ресурса, и по меньшей мере один второй элемент контента, полученный из второго ресурса, отличного от первого ресурса. Данные предоставлены. Идентифицированные результаты поиска и таблица знаний вызывают отображение таблицы знаний на странице результатов поиска Таблица знаний отображает идентифицированный контент в области таблицы знаний параллельно по крайней мере части результатов. Поиск".
Основные функциональные возможности по предоставлению таблицы знаний можно свести к следующим этапам процесса
- Укажите одну или несколько связанных сущностей в поисковом запросе
- Определите основные связанные источники
- Генерировать релевантные результаты поиска, связанные с поисковым запросом
- Проверьте, действительно ли поисковый запрос относится к реальному принципалу
- Указывает тип сущности запрашиваемой основной сущности
- Выберите подходящие шаблоны таблиц знаний, соответствующие указанным типам сущностей
- Определите релевантные элементы контента, связанные с основной сущностью, из соответствующих доверенных источников
- Идентифицировать различные элементы содержания из разных источников.
- Заполните пробелы выбранного шаблона доски знаний выбранным элементом содержимого.
- Объедините результаты поиска и таблицы знаний на одной странице результатов поиска.
Интересно отметить, что каждому типу сущностей присваивается свой собственный шаблон таблицы знаний с соответствующими заполнителями.
Тип сущности соответствующей сущности, представленной в таблице знаний, всегда является
Выбор репрезентативных изображений
В этом патенте описывается, как Google может выбирать репрезентативные изображения для сущностей типа "Лицо" в соответствующей таблице знаний.
Шаги следующие
Доступ к выбору возможных изображений
Группировка на основе сходства
Определение наиболее популярных кластеров
- Определение того, является ли фотография портретом
- Оценка портрета
- Выбор наиболее репрезентативных изображений
- Отображение изображений в таблице знаний
- Выбор возможных изображений и их группировка в категории определяется в соответствии с их близостью к объекту и соотношением размеров. Могут быть использованы методы машинного обучения. Представление о возможных категориях можно получить, изучив поиск изображений.
- Системы и методы для ассоциирования изображений с семантическими сущностями
- Еще один интересный патент Google, связанный с изображениями и сущностями, описывает, как Google Images собирает семантические изображения по умолчанию.
'Реализованные на компьютере система и метод связывают изображения с семантическими сущностями и используют семантические сущности для предоставления результатов поиска. База данных фотографий содержит одно или несколько исходных изображений, связанных с одной или несколькими метками изображений. Компьютер может выдать один или несколько документов, содержащих метки, связанные с каждым изображением. Анализ может быть выполнен для одного или большинства документов, чтобы связать исходные изображения с семантическими сущностями. Семантические сущности могут быть использованы для предоставления результатов поиска. Можно сравнивать с изображениями идентификации по изображениям для выявления похожих изображений. Может использовать семантические сущности, связанные с похожими изображениями, для идентификации семантических сущностей в целевом изображении. Может использовать целевые изображения для предоставления результатов поиска с поисковыми ответами, инициированными с целевого изображения".
В этом патенте изображения выделяются с помощью особенностей. Изображения могут быть сопоставлены с конкретными сущностями. Эти признаки сначала определяются путем распознавания исходного изображения. Дополнительные признаки добавляются через похожие изображения и похожие признаки сущностей, возможно, одного и того же типа. Таким образом, раскрывается смысл изображения.
Эти патенты описывают несколько подходов к тому, как Google может идентифицировать изображения в таблице знаний. На мой взгляд, источник изображения также имеет решающее значение, и Google выбирает изображение, которое он выбрал как наиболее релевантное для данной сущности и поэтому использует в таблице знаний.
Популярными источниками изображений людей являются Викиданные, Википедия, Викимедиа, профили социальных сетей (например, LinkedIn, Twitter) и известные журналы. Неясно, в какой степени ранжирование поиска изображений связано с выбором изображений или картинок в таблице знаний.
Влияние Графа знаний быстро растет
Влияние функциональности SERP растет с каждым годом, тем самым увеличивая влияние графа знаний на результаты поиска. Классические синие ссылки все больше теряют свое внимание и, следовательно, свою значимость.
Сущности занимают центральное место в графе знаний и оказывают все большее влияние на SERP.
Что касается голосового поиска, то здесь важную роль играют такие функции SERP, как функциональные сниппеты и таблицы знаний.
Изменения в SERP в связи с обновлениями mama уже заметны, как и все более центральная роль поиска на основе сущностей.
Поэтому SEOS не должна рассматривать этот вопрос как "приятное дополнение". Граф знаний должен быть включен в стратегию SEO.